


杠杆炒股,股票融资!

发布日期:2024-08-01 11:06 点击次数:132

文|孙欣
裁剪|姚赟
扎克伯格瞻望,Meta AI助手使用率几个月后将超越ChatGPT。
7月24日凌晨,好意思国科技巨头Meta推出迄今为止性能最开阔的开源大模子——Llama 3.1 405B(4050亿参数),同期发布了全新升级的Llama 3.1 70B和8B模子版块。
Llama 3.1 405B复旧高下文长度为128K tokens,是全球迄今为止性能最开阔、参数边界最大的开源模子,在基于15万亿个tokens、超1.6万个H100 GPU上进行磨练,这亦然Meta有史以来第一个以这种边界进行磨练的Llama模子。
因性能佳、开源、多方相助,咫尺所有Llama模子版块的总下载量依然终点3亿次。照看东谈主员基于超150个基准测试集的评测为止夸耀,Llama 3.1 405B可与GPT-4o、Claude 3.5 Sonnet和Gemini Ultra等业界头部模子相比好意思,包括亚马逊AWS、英伟达、微软Azure和谷歌云等25家头部公司与Meta达成相助,引入Llama 3.1。
“这对于咱们来说是亢旱逢甘雨。”独处分析师Jimmy告诉《中国企业家》。苦于零落长久高质地的磨练数据已久,全球AI领域的竖立东谈主员终于迎来了开源晨曦。一般来说,较小的行家模子(参数边界在10亿~100亿)经常运用“蒸馏时刻”,也等于运用更大的模子来增强磨练数据。但由于巨头OpenAI的闭源,此类磨练数据的零落是各大模子共同的穷困。
开、闭源之争一直是AI圈的中心话题。Meta首创东谈主、CEO扎克伯格提到:“我服气Llama 3.1的发布将成为行业的一个飞舞点”;360集团首创东谈主周鸿祎曾经示意,开源社区蚁合全球上千家公司、数十万方法员和工程师,竖立力量是一个闭源公司的数百倍。
扎克伯格开源Llama 3.1,逼急OpenAI
Meta公布前一天,Llama 3.1的模子和基准测试为止依然在海外的Reddit等社区上泄露,Llama 3.1的磁力蚁合也被流传,“开阔”“开源”成为指摘区的高频词。
Llama 3.1包含8B、70B和405B三种参数边界,其中超大杯4050亿版块,该系列模子高下文窗口增多到了128K,扩大16倍;增多了8种复旧言语;种植了用具使用才略,复旧搜索和Wolfram Alpha的数学推理;领有更宽松的许可,允许使用模子输出改良其他LLMs。
事实上,开、闭源的大模子差距正在减轻。Meta在官博指出最新一代的Llama将引发新的应用方法和建表率式,包括运用合成数据生成来种植和磨练更小的模子,以及模子蒸馏——这是一种在开源领域从未有过的才略。在基准测试荟萃的表露确切不错比好意思现时顶尖闭源模子GPT-4o和Claude 3.5 Sonnet,而且所有版块齐不错在官网下载使用。
Meta对Llama 3.1的布局在本年4月就有迹可循。其时Meta就泄漏说,正在竖立东谈主工智能行业的第一款家具:一个性能与OpenAI等公司最佳的独特模子相比好意思的开源模子。
比较于OpenAI对时刻细节的“惜墨如金”,Meta这次不仅通达小助手应用在线试玩,还发布了近100页的醒目论文,涵盖了创造Llama 3.1经过中的一切,比如磨练数据、过滤、退火、合成数据,并泄漏Llama 4已在竖立中。
扎克伯格亲身为开源大模子Llama 3.1站台,在推特撰写长文《Open Source AI Is the Path Forward》强调开源的道理,他示意:“今天咱们正迈出下一步——使开源AI成为行业步伐。”在特斯拉前AI总监对于Llama 3.1大模子的帖子底下,马斯克目生地盛赞扎克伯格:“这令东谈主印象深远,扎克(伯格)的开源决定确乎值得传颂。”
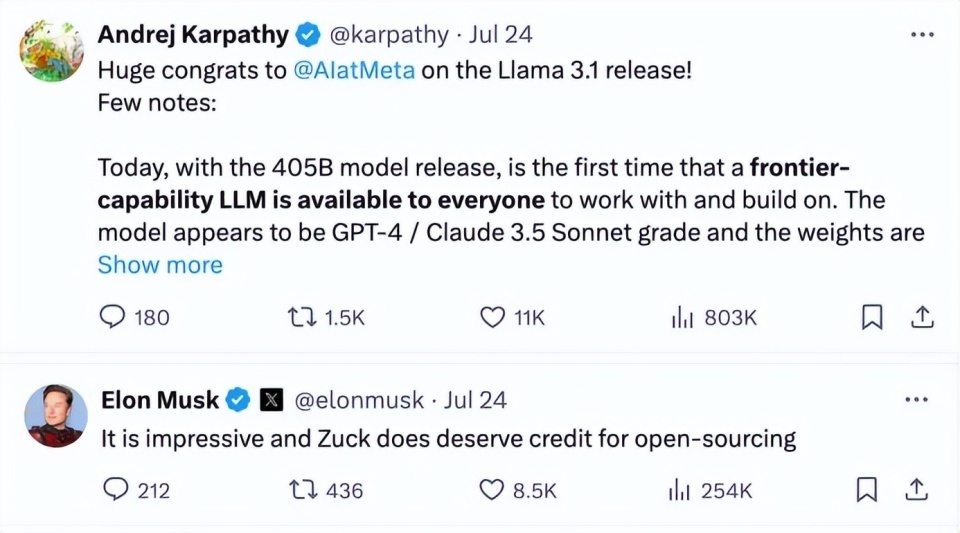
开端:马斯克恢复推特截图
Meta与OpenAI分手代表着开源与闭源的两条时刻道路。对于开源和闭源的战役由来已久,此前在彭博社的采访中,扎克伯格更是公开嘲讽:“阿尔特曼的相似才略值得赞叹,但有点讥讽的是公司名为OpenAl却成为构建顽固式东谈主工智能模子的相似者。”

开端:彭博社X(原推特)截图
濒临Meta这次的大招,OpenAI以廉价政接应战。
Meta公布Llama 3.1两个多小时后,OpenAI发布讯息:公司推出了GPT-4o mini微调功能版,从咫尺到9月23日可免费使用。据了解,GPT-4o mini的输入tokens用度比GPT-3.5 Turbo 低90%,输出tokens 用度低80%。即使免费期收尾,GPT-4o mini的价钱也比GPT-3.5 Turbo低一半。
价钱打折,但家具才略不打折。据了解,GPT-4o mini比经典版块GPT-3.5 Turbo才略更强,GPT-4o mini的高下文长度为65k tokens,是GPT-3.5 Turbo的四倍,推理高下文长度为128k tokens,是GPT-3.5 Turbo的八倍。
这就意味着,若使用GPT-4o mini微调版,就不错享受:以实惠的使用用度,使用更长的高下文、更奢睿的顶尖大模子。阿尔特曼更是在推特发文示意,GPT-4o mini以1/20的价钱在lmsys上杀青了与GPT-4o接近的性能表露,他还但愿人人能够多多使用GPT-4o mini 微调版块。
这次OpenAI以发布GPT-4o mini 微调版为盾,不仅是对Meta开源大模子紧追不舍的反击,也同期将硅谷AI价钱战的炸药味推得更浓。
用价钱“会剿”OpenAI
即使OpenAI推出可免费使用的小模子,但比起同为大模子的家具,Llama 3.1 405B的价钱比GPT-4o仍然要低好多。
公开数据夸耀,Llama 3.1的价钱在Fireworks平台上是每1百万tokens的输入/输出价钱是3好意思元,而GPT-4o每1百万tokens的输入价钱是5好意思元,黄金投资输出价钱是15好意思元。此外,Claude 3.5 sonnet的每1百万tokens的输入价钱是3好意思元,输出价钱是15好意思元。
这不是硅谷在AI方面的第一次“价钱战”。
本年5月,OpenAI发布GPT-4o并复旧免费试用,调用API的价钱也比GPT-4-Turbo裁减一半——打响了硅谷大模子价钱战第一枪,同期这亦然2023年起OpenAI的第4次降价。7月18昼夜深,GPT-4o mini的追究亮相,与GPT-3.5比较性能更强,也更低廉,连阿尔特曼齐曾建议人人不要再用GPT-3.5了。
用廉价“会剿”OpenAI已成大模子公司们的常规。公开信息夸耀,与GPT-4o比较较,各大公司的最新发布的家具分手是:Meta的Llama 3.1,谷歌的Gemini 1.5 pro,Claude 3 Sonnet,新近的Mistral AI,这些最新大模子价钱均低于GPT-4o。
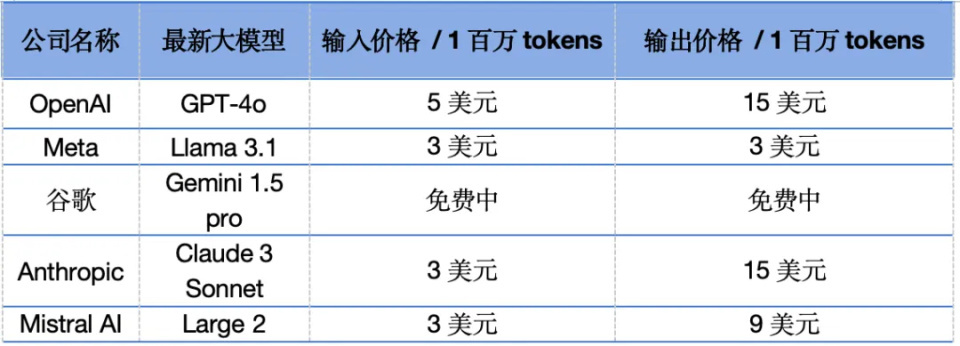
国际头部大模子公司家具价钱表,信息开端各大模子官网。制表:孙欣
而大模子的价钱战在国内也已运转。5月6日,初创大模子公司DeepSeek深度求索将输入价钱定为1元/百万tokens。紧接着智谱AI的GLM-3-Turbo模子、字节终点的豆包大模子,以及阿里巴巴的通义系列模子、百度的文心一言模子纷繁跟牌。
廉价,正在成为一种趋势。
小模子或将成为AI新风口
一直以来,大模子的发展受困于资本。斯坦福HAI照看所发布的《斯坦福2024年东谈主工智能指数知道》指出,AI模子的培训资本依然达到了前所未有的水平。举例,OpenAI的GPT-4臆想使用了7800万好意思元用于计较磨练,而谷歌的Gemini Ultra奢靡了1.91亿好意思元用于计较。2017年磨练率先的Transformer模子的资本仅为约900好意思元。
而咫尺,小模子成了AI公司们降本增效的利器。
掀翻新一轮价钱战前,OpenAI先手开卷小模子。7月18日,OpenAI发布小模子GPT-4o mini,并称其为“迄今为止最具资本效益的小模子”,恰是上周(北京时刻7月25日凌晨)布告免费使用的GPT-4o mini微调版的真身;苹果公司在Hugging Face上发布了DCLM-7B开源小模子;不久后,英伟达和法国明星AI独角兽Mistral长入发布了名为Mistral NeMo的小模子,称不错径直替换任何使用Mistral 7B的系统。
小模子,闲居来说等于比大模子科罚数据才略略小的模子,不错厚实为mini版的大模子。在AI领域,参数边界越大,大模子学习才略越强,诸如GPT-4这些模子经常领终点十亿以致数百亿的参数。有关词据OpenAI先容,小模子GPT-4o mini在MMLU上的得分为82%,以致某些表露优于大模子GPT-4。
对大部分用户来说,小模子是大模子的“平替”,极具性价比。尽管小模子在科罚复杂任务上不具上风,但在小任务上具备更快的推理才略。同期对计较机存储需求也更小,耗能也更小。左证各公司的大、小模子家具对比来看,小模子价钱较低。左证Artificial Analysis的统计,好意思国AI公司主流“小模子”中,GPT-4o mini的价钱最低,在无需科罚复杂任务的“普通用户”中大概将更受接待。
廉价来自资本的裁减。阿尔特曼在推特上发文指出,2022年寰宇上最佳的模子text-davinci-003,它比GPT-4o mini差得多,但资本要贵上100多倍。这一波OpenAI抢先布局小模子,等于念念通过权臣裁减AI使用资本,扩大AI使用范围。
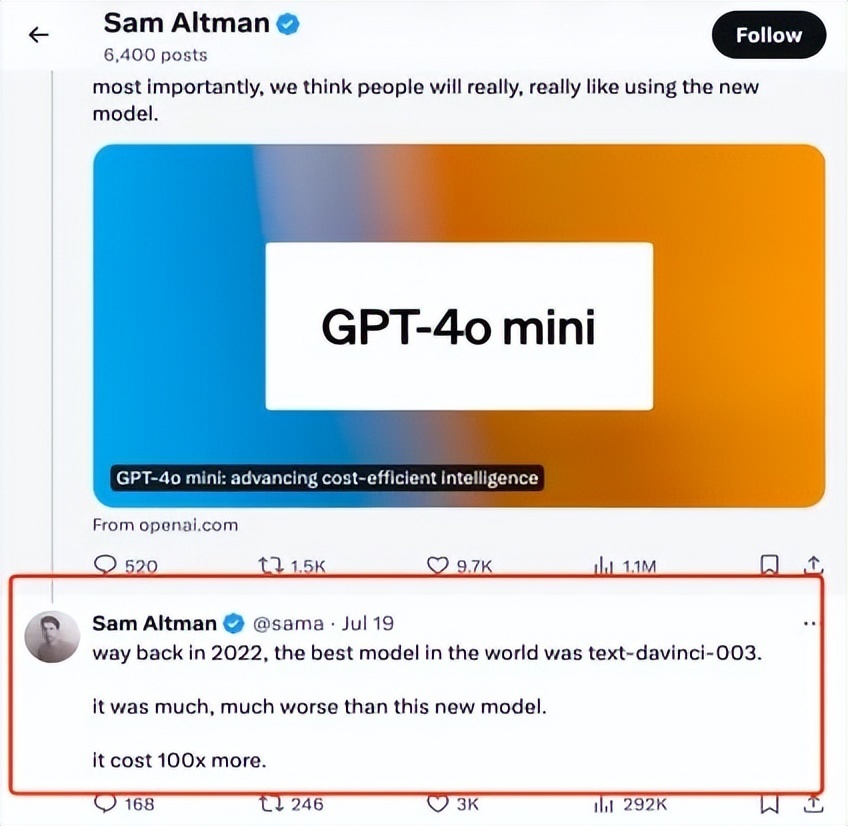
开端:阿尔特曼推特截图
低资本、低性价比、更广用户适配度,小模子不仅能成为AI公司们to C端的有劲技巧,更是AI价钱战的布置神器,或将成为下一个新风口。
本年事首,2024百度AI竖立者大会上,李彦宏提倡以前大型的AI原生应用齐是大小模子的混用。他还示意,用户基于百度文心4.0,不错天真剪裁出适用于不同场景的小尺寸模子,“在一些特定场景中,经过精调后的小模子,其使用后果以致不错比好意思大模子。”
海外GPT-4o、Llama 3.1轮替轰炸,国内“千模大战”大浪淘沙,无论开源如故闭源,高价如故廉价、大模子如故小模子,这波AI波澜临了的胜者还未显现。