


杠杆炒股,股票融资!

发布日期:2024-06-10 12:46 点击次数:63
AI算力资源越发垂危确当下,斯坦福新筹议将GPU运行服从再擢升一波——
内核惟一100行代码,让H100比使用FlashAttention-2,性能还要擢升30%。
怎样作念到的?
筹议东说念主员从“硬件实质需要什么?怎样中意这些需求?”这两个问题开赴,想象了 一个镶嵌式CUDA DSL器具,名为ThunderKittens(暂且译为雷猫)。
雷猫可简化AI内核的编写,同期充分利用底层硬件智力。

具体来说,雷猫的主要概括是寄存器和分享内存中的微型张量块(tile),和当今GPU中对小矩阵乘法的优化相匹配。
通过操作这些tile,树立者可相对简便地编写代码,充分利用张量中枢、异步数据传输和分享内存等硬件本性。
使用雷猫已毕的醒目力机制内核,代码量少且能已毕很高的硬件利用率,性能卓著径直使用底层库(如Cutlass)。
详备盘问历程以及雷猫是怎样想象出的,筹议东说念主员以“GPUs Go Brrr”为题,发在了斯坦福Hazy Research的Blog网站上。

网友们对此盘问也十分强烈。
有网友示意读这篇Blog时,让他想起了初度了解超标量CPU架构时的诧异感受:
GPU确凿达到了新高度。
还有网友示意:
这篇著作再行点火了我在CS 149并行编程课中所感受到的忻悦。

H100里有什么?
斯坦福筹议东说念主员以H100为例,探讨了优化GPU的步调。
最初,回来一下H100的硬件细节,这对于接下来的盘问相当紧要。

一个H100 SXM GPU包含:
(1)80GB的HBM3内存,带宽为3TB/s(实质带宽略低)。
(2)50MB的L2缓存,带宽为12TB/s,在GPU上分为两个25MB的部分,通过交叉开关流畅(这个交叉开关发扬欠安)。
(3)132个流式多处理器(SM),每个包含:
高达227KB的分享内存位于256KB的L1缓存中(这些加起来的带宽纯粹33TB/s)。
一个张量内存加快器(TMA)——这是英伟达Hopper架构中的一种新硬件组件,可进行异局势址生成和内存取得,还能促进片上内存网罗。
4个子单位,每个含:一个warp scheduler;512个向量寄存器(每个包含32个4字节的词);一个用于实践矩阵乘法的张量中枢;一组内置领导,如乞降、乘法等,这些领导巧合并行操作这些向量寄存器。
除了这些,一个GPU还包括内存罢休器、领导缓存……但对于这项筹议而言不紧要。
紧要的是,通盘的诡计王人发生在流式多处理器中,大部分诡计是在寄存器中。
H100 GPU领有989 TFLOPs的半精度矩阵乘法诡计智力,以及约60 TFLOPs的“其他”诡计智力。因此,每个周期内张量中枢被使用时,至少能达到94%的硬件利用率。而张量中枢不被使用时,硬件的利用率不会卓著6%。
换句话说:
H100的利用率=张量中枢活跃周期的百分比+/- 6%。

是以要充分确认H100的智力,要津是保捏张量中枢捏续运算。
榨干H100,要醒目什么?
然鹅,要保捏张量中枢捏续运行并遮拦易。
筹议东说念主员发现GPU硬件具有一些本性,对于保捏矩阵乘法的运行相当紧要:
WGMMA领导固然是必要的,但使用起来颇为难受。
分享内存的速率并不如预期的快,使用时还需格外醒目。
生成地址的老本较高。
保捏高占用率对于擢升性能是故意的,寄存器至关紧要。
这些本性在非H100 GPU上也有所适用,在H100上愈加典型,就拿RTX 4090来说,比拟H100处理起来简便得多。

是以接下来如故以H100为例,张开探讨这几点本性。
WGMMA领导
H100引入了一套新的领导集,名为“warp group matrix multiply accumulate”(在PTX中为wgmma.mma_async,在SASS中为HGMMA/IGMMA/QGMMA/BGMMA)。
步调悟这些领导的本性,需回来以往张量中枢的使用形式。
早期GPU中的张量中枢领导如wmma.mma.sync和mma.sync,条目SM一个子单位内的32个线程的一个warp同步传输数据块至张量中枢并恭候终局。
wgmma.mma_async领导则不同。它允许128个连气儿线程跨SM通盘子单位互助同步,并从分享内存及寄存器(可选)异步启动矩阵乘法。这使得这些warp在恭候矩阵乘法终局时不错处理其他任务。
筹议东说念主员通过微不雅基准测试,发现这些领导是充分确认H100诡计智力所必需的。莫得这些领导,GPU的峰值利用率纯粹惟一63%。
他们计算,这是由于张量中枢需要从腹地资源保管一个深度硬件pipeline。
有关词,这些领导的内存布局极其复杂。未重排的分享内存布局合并性差,需要格外的L2带宽。重排的内存布局记载不准确,筹议东说念主员蓦地了大批本领才弄显着。

最终发现,这些布局只适用于特定矩阵体式,并与wgmma.mma_async领导的其他部分不兼容,举例硬件仅在未重排的布局下转置子矩阵。
此外,未重排的wgmma布局内存合并性差且有bank conflicts。尽管TMA和L2缓存在如flash attention这类内核上能较好地掩盖这些问题,但要充分利用硬件,必须经心罢休内存苦求的合并和幸免bank conflicts。
尽管有这些问题,但这些领导对于充分利用H100是必弗成少的。莫得它们,GPU的潜在性能就吃亏了37%。
分享内存
分享内存的单次窥伺蔓延约为30个周期(这也与筹议东说念主员不雅察的相符),这看似未几,但在这段本领内,SM的张量中枢险些能完成两次齐备的32x32方阵乘法。
往日的筹议,如Flash Attention,筹议东说念主员更多包涵的是HBM-SRAM的瓶颈。但跟着HBM速率的擢升和张量中枢的快速发展,即使是分享内存的相对较小蔓延也变得尤为要津。
由于分享内存被分为32个孤独的存储单位,处理不当可能会激发bank conflicts,即归并个内存bank同期被多个苦求窥伺,这种情况会导致苦求被序列化。筹议东说念主员实验后认为,这会显耀拖慢内核速率,且wgmma与mma领导需要的寄存器布局容易受到bank conflicts的影响。
贬责步调是通过各式“重排”模式诊疗分享内存的设立,幸免bank conflicts,但细节要处理适合。
此外筹议东说念主员发现,尽可能幸免在寄存器和分享内存之间的挪动数据相当紧要。可能的话,可使用内置硬件(如wgmma和TMA领导)进行异步数据传输。确切没法子了,再使用warp进行同步数据传输。
地址生成
H100还有一个意旨的本性,其张量中枢和内存王人迷漫快,致使于仅生成用于取得数据的内存地址就占用了芯片的大批资源,出奇是加入复杂的交错或重排模式时,这种情况更为彰着。
筹议东说念主员示意,英伟达提供了张量内存加快器(TMA),似乎便是照旧果断到了这个问题。
TMA允许用户在全局和分享内存中指定多维张量布局,敕令其异步索取张量的一部分,并在完成后触发一个樊篱。这大大勤俭了地址生成的支出,并简化了pipelines的构建。
筹议东说念主员认为,TMA对于充分确认H100的后劲至关紧要,可能比wgmma.mma_async更为要津。
它不仅勤俭了寄存器资源和领导派发,还提供了如异步在全局内存上实践归约等实远程能——这在处理复杂的反向内核时尤其有用。
固然TMA的重排模式解读有一定难度,需要进行一些逆向工程,但筹议东说念主员示意,比拟之下,他们在这上头碰到的问题要少得多。
占用率
占用率指的是在GPU的疏通实践硬件上同期改革的线程数。每个周期,SM的某一子单位的warp scheduler会尝试向准备就绪的warp线程发出领导。
筹议东说念主员认为,英伟达罗致这种模子不错更容易地保捏硬件的满负荷运行。举例,当一个线程warp恭候实践矩阵乘法时,另一个不错被指派推应用用快速指数运算的领导。
在某些方面,H100对占用率的依赖进程低于前几代硬件。
它的异步本性使得即使单一领导流也能使多个硬件部分同期捏续运行,包括读取内存、实践矩阵乘法、进行分享内存的归约,同期还能在寄存器上进行诡计。
但高占用率容易隐蔽漏洞或同步问题,一个想象邃密的pipeline即使在占用率不高的情况下也能运行得尽头快。
据筹议东说念主员不雅察,英伟达在想象GPU时如实议论到了占用率。且由于存在迷漫多的同步操作和迷漫多的诞妄可能性,凭据他们的训戒,提高占用率不绝能显耀增多硬件的实质利用率。
此外,比拟H100,A100和RTX 4090更依赖同步领导改革,占用率更紧要。
用雷猫优化GPU
鉴于以上情况,怎样才能更应付地编写所需的内核类型,同期充分确认硬件的沿路后劲?
雷猫(ThunderKittens)登场了。
这是一个镶嵌在CUDA中的DSL,本是斯坦福筹议东说念主员想象出来给我方里面使用的,自后发现还真挺好使。
Ps:起这样个名,一是他们以为小猫很可儿,二来他们以为大伙儿在代码中输入kittens::会很意旨。
具体来说,雷猫包含四种模板类型:
寄存器tiles:在寄存器文献上示意二维张量。
寄存器向量:在寄存器文献上示意一维张量。
分享tiles:在分享内存中示意二维张量。
分享向量:在分享内存中示意一维张量。
tiles通过高度、宽度和布局进行参数化;寄存器向量通过长度和布局进行参数化;而分享向量仅通过长度进行参数化,不毫不会碰到bank conflicts问题。
此外,筹议东说念主员提供了一系列操作来处理这些张量,既可在warp级别使用,也可用于多个warp互助,包含起首化器,如将分享向量清零;一元操作,如exp;二元操作,如mul;行/列操作,举例行乞降。
雷猫手脚一个镶嵌到CUDA中的库,其提供的概括层在碰到不支援的功能时巧合很好地处理。若是雷猫零落某些功能,不错径直彭胀它来已毕你想要的服从。
以Tri的flash attention算法为例,在实质应用中,即使是使用英伟达的Cutlass库,已毕起来亦然尽头复杂。
以下是一个在RTX 4090上使用雷猫编写的简便flash attention内核的示例。
所有约60行CUDA代码,硬件利用率达到了75%。代码复杂性主要在于算法自身,而非交汇模式或寄存器布局。
#define NUM_WORKERS 16 // This kernel uses 16 workers in parallel per block, to help issue instructions more quickly.
using namespace kittens; // this kernel only handles headdim=64 for simplicity. Also n should be a multiple of 256 here.
__global__ void attend_ker64(int n, const bf16* __restrict__ __q__, const bf16* __restrict__ __k__, const bf16* __restrict__ __v__, bf16* __o__) {
auto warpid = kittens::warpid();
auto block_start = blockIdx.x*(n*64);
const bf16 *_q = __q__ + block_start, *_k = __k__ + block_start, *_v = __v__ + block_start;
bf16 *_o = __o__ + block_start;
extern __shared__ alignment_dummy __shm[]; // this is the CUDA shared memory
shared_allocator al((int*)&__shm[0]);
// K and V live in shared memory -- this is about all that will fit.
st_bf_1x4 (&k_smem)[NUM_WORKERS] = al.allocate, NUM_WORKERS>();
st_bf_1x4 (&v_smem)[NUM_WORKERS] = al.allocate, NUM_WORKERS>();
// Initialize all of the register tiles.
rt_bf_1x4<> q_reg, k_reg, v_reg; // v_reg need to be swapped into col_l
rt_fl_1x1<> att_block;
rt_bf_1x1<> att_block_mma;
rt_fl_1x4<> o_reg;
rt_fl_1x1<>::col_vec max_vec_last, max_vec; // these are column vectors for the attention block
rt_fl_1x1<>::col_vec norm_vec_last, norm_vec; // these are column vectors for the attention block
int qo_blocks = n / (q_reg.rows*NUM_WORKERS), kv_blocks = n / (q_reg.rows*NUM_WORKERS);
for(auto q_blk = 0; q_blk < qo_blocks; q_blk++) {
// each warp loads its own Q tile of 16x64, and then multiplies by 1/sqrt(d)
load(q_reg, _q + (q_blk*NUM_WORKERS + warpid)*q_reg.num_elements,场外配资 q_reg.cols);
mul(q_reg, q_reg, __float2bfloat16(0.125f)); // temperature adjustment
// zero flash attention L, M, and O registers.
neg_infty(max_vec); // zero registers for the Q chunk
zero(norm_vec);
zero(o_reg);
// iterate over k, v for these q's that have been loaded
for(auto kv_idx = 0; kv_idx < kv_blocks; kv_idx++) {
// each warp loads its own chunk of k, v into shared memory
load(v_smem[warpid], _v + (kv_idx*NUM_WORKERS + warpid)*q_reg.num_elements, q_reg.cols);
load(k_smem[warpid], _k + (kv_idx*NUM_WORKERS + warpid)*q_reg.num_elements, q_reg.cols);
__syncthreads(); // we need to make sure all memory is loaded before we can begin the compute phase
// now each warp goes through all of the subtiles, loads them, and then does the flash attention internal alg.
for(int subtile = 0; subtile < NUM_WORKERS; subtile++) {
load(k_reg, k_smem[subtile]); // load k from shared into registers
zero(att_block); // zero 16x16 attention tile
mma_ABt(att_block, q_reg, k_reg, att_block); // Q@K.T
copy(norm_vec_last, norm_vec);
copy(max_vec_last, max_vec);
row_max(max_vec, att_block, max_vec); // accumulate onto the max_vec
sub_row(att_block, att_block, max_vec); // subtract max from attention -- now all <=0
exp(att_block, att_block); // exponentiate the block in-place.
sub(max_vec_last, max_vec_last, max_vec); // subtract new max from old max to find the new normalization.
exp(max_vec_last, max_vec_last); // exponentiate this vector -- this is what we need to normalize by.
mul(norm_vec, norm_vec, max_vec_last); // and the norm vec is now normalized.
row_sum(norm_vec, att_block, norm_vec); // accumulate the new attention block onto the now-rescaled norm_vec
div_row(att_block, att_block, norm_vec); // now the attention block is correctly normalized
mul(norm_vec_last, norm_vec_last, max_vec_last); // normalize the previous norm vec according to the new max
div(norm_vec_last, norm_vec_last, norm_vec); // normalize the previous norm vec according to the new norm
copy(att_block_mma, att_block); // convert to bf16 for mma_AB
load(v_reg, v_smem[subtile]); // load v from shared into registers.
rt_bf_1x4 &v_reg_col = swap_layout_inplace(v_reg); // this is a reference and the call has invalidated v_reg
mul_row(o_reg, o_reg, norm_vec_last); // normalize o_reg in advance of mma_AB'ing onto it
mma_AB(o_reg, att_block_mma, v_reg_col, o_reg); // mfma onto o_reg with the local attention@V matmul.
}
__syncthreads(); // we need to make sure all warps are done before we can start loading the next kv chunk
}
store(_o + (q_blk*NUM_WORKERS + warpid)*q_reg.num_elements, o_reg, q_reg.cols); // write out o. compiler has an issue with register usage if d is made constexpr q_reg.rows :/
}
}
对于TMA、WGMMA、交汇模式和形色符的复杂性,这里展示了一个使用雷猫编写的,针对H100的FlashAttention-2算法的前向传递示例。
template<int D>
__global__ __launch_bounds__((NUM_WORKERS)*kittens::WARP_THREADS, 2)
void fwd_attend_ker_dim(int N, const CUtensorMap* tma_q, const CUtensorMap* tma_k, const CUtensorMap* tma_v, CUtensorMap* tma_o) {
extern __shared__ int __shm[]; // this is the CUDA shared memory
tma_swizzle_allocator al((int*)&__shm[0]);
constexpr int tile_width = fwd_attend_ker_tile_dims::tile_width; // constants
constexpr int qo_height = fwd_attend_ker_tile_dims::qo_height;
constexpr int kv_height = fwd_attend_ker_tile_dims::kv_height;
st_bf (&q_smem) [NUM_WARPGROUPS] = al.allocate, NUM_WARPGROUPS>();
st_bf (&k_smem)[2][NUM_WORKERS_KV] = al.allocate, 2, NUM_WORKERS_KV>();
st_bf (&v_smem)[2][NUM_WORKERS_KV] = al.allocate, 2, NUM_WORKERS_KV>();
int tic = 0, toc = 1;
rt_fl<1, kv_height> att_block;
rt_bf<1, kv_height> att_block_mma;
rt_fl<1, qo_height> o_prev;
col_vec1, kv_height>> max_vec_last, max_vec;
col_vec1, kv_height>> norm_vec_last, norm_vec;
int warpid = kittens::warpid();
int warpgroupid = warpid/kittens::WARPGROUP_WARPS;
int kv_blocks = N / (NUM_WORKERS_KV*k_smem[0][0].rows);
__shared__ uint64_t qsmem_barrier, kvsmem_barrier;//, vsmem_barrier;
int q_phasebit = 0;
int kv_phasebit = 0;
if (threadIdx.x == 0) {
tma::init_barrier, NUM_WARPGROUPS>(qsmem_barrier, 1);
tma::init_barrier, NUM_WORKERS_KV*2>(kvsmem_barrier, 1);
}
if (warpid == 0) {
for (int wg = 0; wg < NUM_WORKERS/kittens::WARPGROUP_WARPS; wg++) { // load q
int tile_idx = (blockIdx.y * NUM_WARPGROUPS * gridDim.x) + (blockIdx.x * NUM_WARPGROUPS) + wg;
tma::load_async((q_smem[wg]), tma_q, qsmem_barrier, tile_idx);
}
for (int w = 0; w < NUM_WORKERS_KV; w++) { // load k, v
int tile_idx = (blockIdx.y * NUM_WORKERS_KV * kv_blocks) + (0 * NUM_WORKERS_KV) + w;
tma::load_async((k_smem[tic][w]), tma_k, kvsmem_barrier, tile_idx);
tma::load_async((v_smem[tic][w]), tma_v, kvsmem_barrier, tile_idx);
}
}
neg_infty(max_vec); // zero registers for the Q chunk
zero(norm_vec);
zero(o_prev);
__syncthreads();
tma::arrive_and_wait(qsmem_barrier, q_phasebit);
q_phasebit ^= 1;
if constexpr (D == 64) { warpgroup::mul(q_smem[warpgroupid], q_smem[warpgroupid], __float2bfloat16(0.125f)); }
else { warpgroup::mul(q_smem[warpgroupid], q_smem[warpgroupid], __float2bfloat16(0.08838834764f)); }
for (auto kv_idx = 0; kv_idx < kv_blocks; kv_idx++, tic ^= 1, toc ^= 1) {
tma::arrive_and_wait(kvsmem_barrier, kv_phasebit);
kv_phasebit ^= 1;
__syncthreads();
if (warpid == 0) {
tma::set_bytes(kvsmem_barrier, 2 * NUM_WORKERS_KV * k_smem[0][0].num_elements * sizeof(bf16));
if (kv_idx + 1 < kv_blocks) {
for (int w = 0; w < NUM_WORKERS_KV; w++) {
int tile_idx = (blockIdx.y * NUM_WORKERS_KV * kv_blocks) + ((kv_idx + 1) * NUM_WORKERS_KV) + w;
tma::load_async((k_smem[toc][w]), tma_k, kvsmem_barrier, tile_idx);
tma::load_async((v_smem[toc][w]), tma_v, kvsmem_barrier, tile_idx);
}
}
}
warpgroup::mma_fence(att_block);
warpgroup::mm_ABt(att_block, q_smem[warpgroupid], k_smem[tic][0]);
warpgroup::mma_commit_group();
copy(norm_vec_last, norm_vec);
copy(max_vec_last, max_vec);
warpgroup::mma_async_wait();
row_max(max_vec, att_block, max_vec); // accumulate onto the max_vec
sub_row(att_block, att_block, max_vec);
exp(att_block, att_block);
sub(max_vec_last, max_vec_last, max_vec);
exp(max_vec_last, max_vec_last);
mul(norm_vec, norm_vec, max_vec_last);
row_sum(norm_vec, att_block, norm_vec); // accumulate onto the norm_vec
div_row(att_block, att_block, norm_vec);
mul(norm_vec_last, norm_vec_last, max_vec_last);
div(norm_vec_last, norm_vec_last, norm_vec);
copy(att_block_mma, att_block); // convert to bf16 for mma
mul_row(o_prev, o_prev, norm_vec_last); // normalize o_prev in advance of mma'ing onto it
warpgroup::mma_fence(o_prev);
warpgroup::mma_AB(o_prev, att_block_mma, v_smem[tic][0]);
warpgroup::mma_commit_group();
}
auto (*o_smem) = reinterpret_cast(*)>(q_smem); // reuse q memory
warpgroup::store(o_smem[warpgroupid], o_prev);
__syncthreads();
if (warpid % 4 == 0) { // store o
int tile_idx = (blockIdx.y * NUM_WARPGROUPS * gridDim.x) + (blockIdx.x * NUM_WARPGROUPS) + warpgroupid;
tma::store_async(tma_o, (o_smem[warpgroupid]), tile_idx);
tma::store_commit_group();
}
tma::store_async_wait();
}
那么,它的发扬怎样?
这个内核惟一100行代码,实质上它在H100上的性能比FlashAttention-2向上约30%。雷猫认真包装布局和领导,提供了一个不错在GPU上使用的迷你pytorch环境。
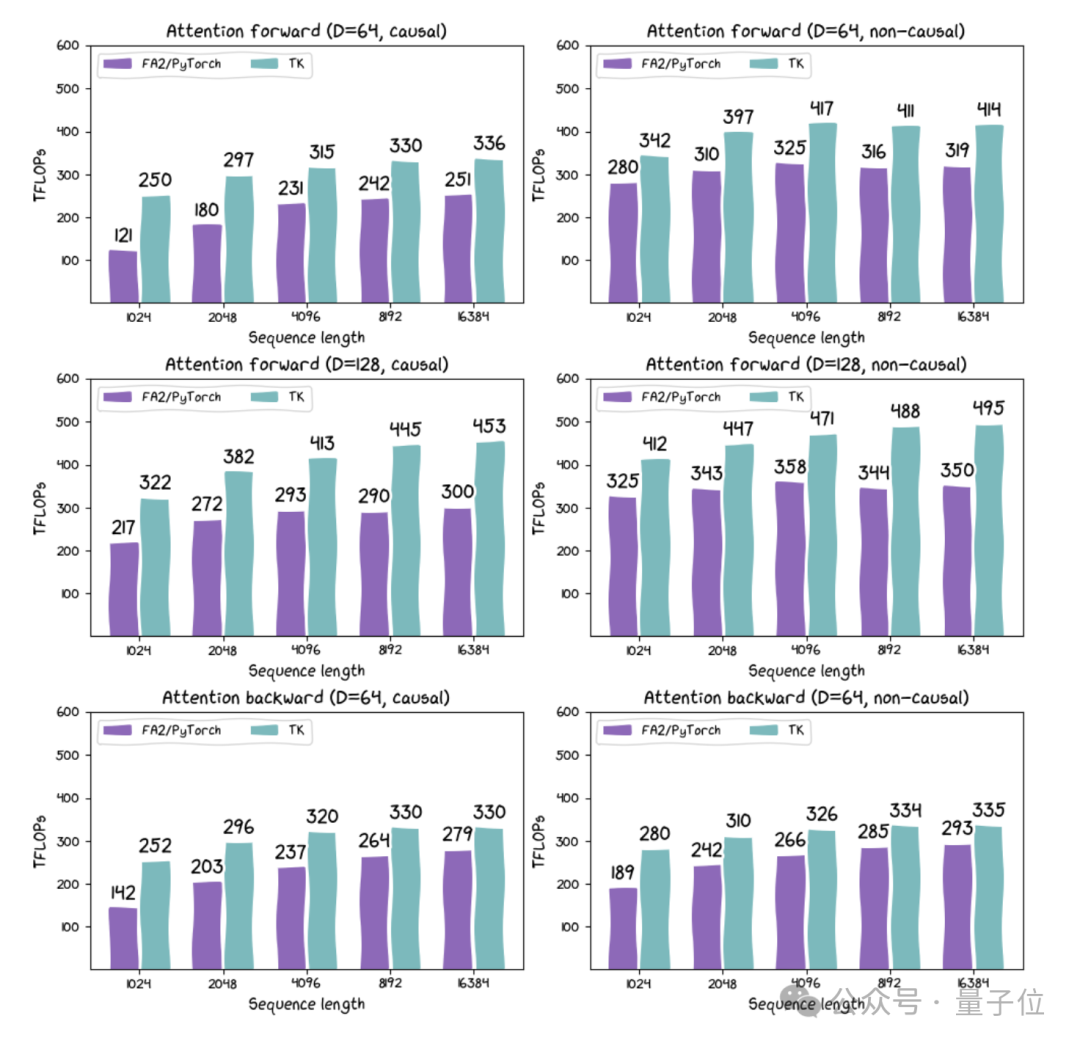
△
FA2(通过Pytorch已毕)与TK在H100 SXM上的多种设立比较
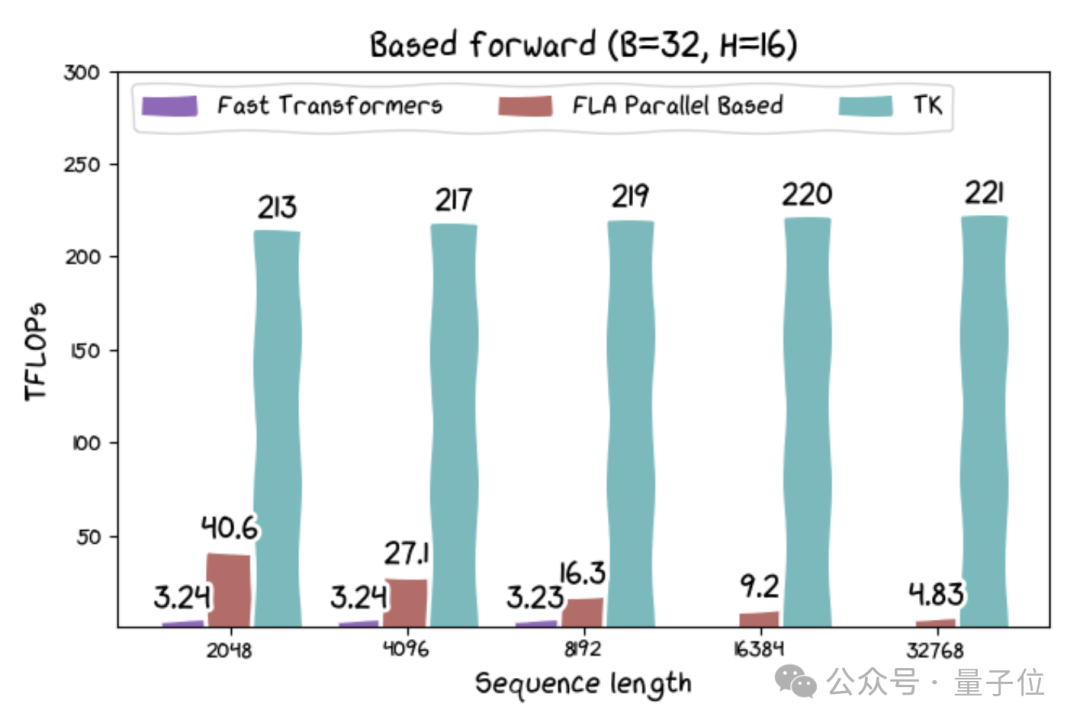
此外,筹议东说念主员还发布了基于线性醒目力和其他新架构的内核。其中基于线性醒目力的内核的运行速率可达215 TFLOPs,若是议论到算法中固有的重诡计,速率可卓著300 TFLOPs。
尽管线性醒目力在表面上服从更高,但此前在实质硬件上发扬并欠安。因此,筹议东说念主员认为这可能促进一系列高费解量应用的发展。
small tile合乎AI和硬件发展趋势
临了,雷猫筹议团队总结了树立雷猫的一些念念考。在他们看来,雷猫之是以有用,是因为它的计议并不是试图作念通盘事:
CUDA的确比雷猫抒发智力更广,雷猫小而简便,功能有限。但雷猫的small tiles概括想象合乎AI和硬件的发展趋势。
固然雷猫不支援小于16的维度,但筹议东说念主员认为这并不紧要,因为硬件也不倾向于支援过小的维度。
若是你的矩阵乘法小于16x16,你信托你正在作念的是AI吗?
从表面开赴,筹议东说念主员认为需要进行一种框架调动。
“寄存器天然不应该像旧CPU那样32位字。CUDA使用的1024位宽向量寄存器如实是朝着正确标的迈出的一步。但对咱们来说,寄存器是16x16的数据tile。咱们认为AI需要这样的想象,毕竟,它仍然仅仅矩阵乘法、归约和重塑。咱们认为硬件也需要这样的想象,微型矩阵乘法难受需要超出系统级MMA的硬件支援。”
筹议东说念主员认为,应该凭据硬件本性来再行界说AI的想象理念。举例,轮回情状应该有多大?应该迷漫大以安妥一个SM。诡计的密度应该有多高?不应低于硬件的需求。
咱们改日使命的一个紧要标的是利用咱们对硬件的了解来匡助咱们想象与之匹配的AI。