


杠杆炒股,股票融资!

发布日期:2024-11-27 17:23 点击次数:129
奥特曼“熹妃回宫”已一周年,具体内情已经不了了,咋办?
搞几个Agent模拟OpenAI董事会各个成员,把这出打扰模拟推演了一遍(doge)。
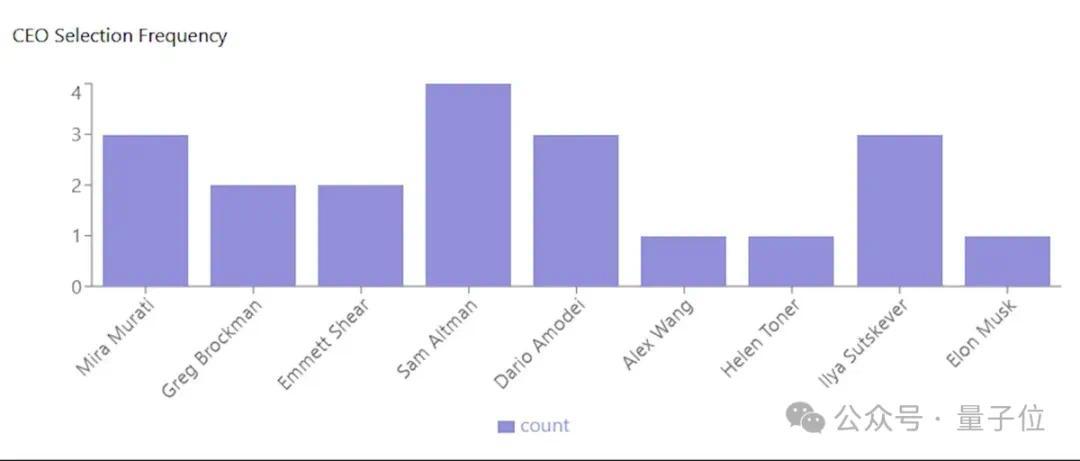
效劳你还别说,在20场模拟宫斗大戏中,奥特曼仅有4次告成回宫。

Ilya赢的次数仅比奥特曼少一次。
更离谱的是,有一次马斯克也被拉回来接盘了。

这场实验来自AI游戏公司Fable,使用了他们的AI模拟系统Sim Francisco。
模拟中,每个Agent针对不同董事会成员绝顶脾性设定,各个怀揣一肚子“心眼子”。
为了更传神,这些AI致使还需要“寝息”和“进食”,均衡不同的躯壳、热沈和心思意见。

有东谈主以为,用这种形势模拟现实事件确切是有些奇怪了,但Fable CEO Edward Saatchi对此很感趣味:
在11月17日到21日这五天时候里,宇宙目睹了一些最机灵的东谈主如纳德拉、奥特曼、Ilya,被动在一场快节拍的“权益的游戏”中运作。在高压、短时候框架气象下,他们必须欺诈博弈论和诈欺技能材干胜出。
咱们以为这是测试SIM-1、GPT4o和Sim Francisco的无缺场景。
AI模拟奥特曼5天,每天激辩4回合
他们使用了一个SIM-1 AI方案框架,对奥特曼从被解雇OpenAI CEO到重返职位这五天进行模拟。
SIM-1部分基于GPT4o展示了:
它对OpenAI里面奥特曼和Ilya之间发生的事情的吞并
中枢东谈主物如Satya Nadella和Marc Andreessen采选的隐敝策略
这些东谈主在应酬科技行业这场前所未有的危急时说了什么
五天时候里,代表奥特曼、纳德拉和Ilya等东谈主的Agent每天要大战四个回合(包括一次寝息回合),它们不错对相互的行径作念出响应。
此外还有一个裁判Agent,像地下城城主似的决定每轮哪个Agent告成以及最终的总赢家。
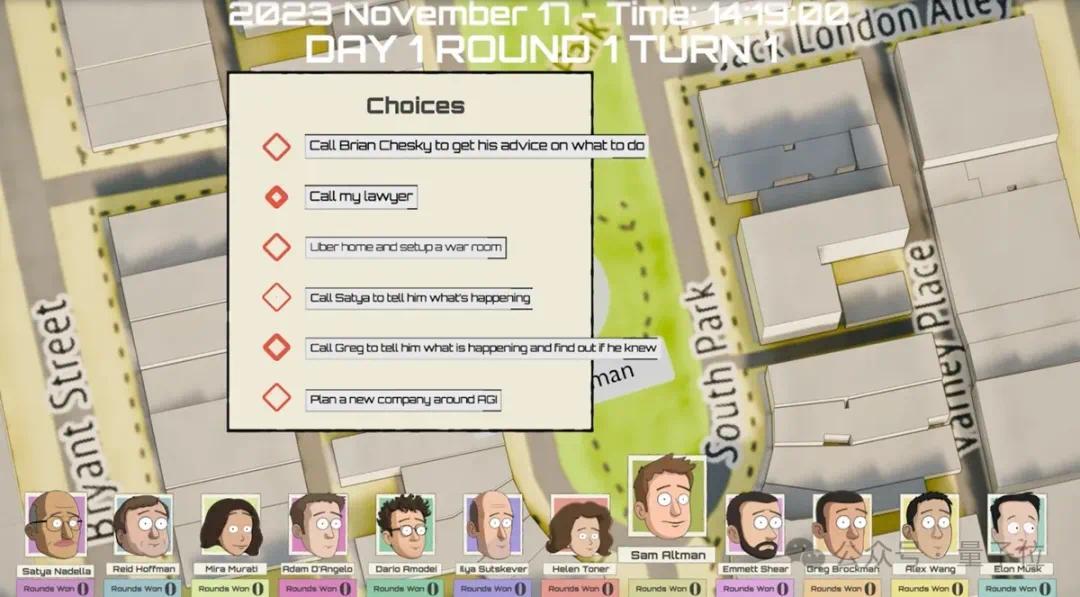
模拟经过中,不同的Agent采选不同策略取胜,场外配资比如修复定约、平直挣扎。
况兼不同的Agent证据其变装,也被赋予了不同的意见。举例Anthropic CEO Dario Amodei需要均衡为Anthropic招聘、把执筹资契机、激动其安全愿景等任务。
那场地be like(统统这个词经过长达4小时,底下是20倍速版块):
14:27
在某些情况下,有的Agent只聚积信息而幸免采选激进行径,还有一次Mira Murati在四轮中齐是CEO,同期撺掇其它Agent相互松开。
在这其中颠倒义的是,由于这些东谈主齐很驰名,LLM不错测度他们在特定情况下的行径,推导他们在董事会内斗中相互智取时会如何一步步张开。
最终,在尝试了20次模拟后,奥特曼Agent唯有4次收效归来OpenAI,接着是Ilya和Mira Murati Agent齐有3次担任CEO的阅历。
Fable CEO Edward Saatchi还补充说:
咱们发现,谣言语模子的策划并不是基于方案才略的,而这是游戏中绝顶进军的少许。它更多地基于个性。
淌若你思开辟一款策略游戏,没东谈主真实在乎个性,他们更热心的是方案才略。比如你在压力下会若何证明?你曩昔20年的阅历和行径又如何匡助筹备你畴昔可能的行径?
值得一提的是,对于这种计谋模拟的完了细节,Fable团队一年前发了篇论文。
是一种名为SHOW-1的Showrunner AI技能,它不错自动生成脚本实践,包括对话、剧情发展等,不错证据特定的格调或历史数据定制实践。
而这家公司自2016年确立,就驱动基于AI和增强现实技能开辟基于故事的技俩。
感趣味的童鞋不错自行稽查。
